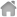完成函数
size_t foo(unsigned int *a1, size_t al1, unsigned int* a2, size_t al2)
其中a1和a2都为无符号数组,al1和al2为数组的长度,数组的长度为偶数。
无符号数组由一对数字区间组成。如下例:
a1 为 0,1,3,6,10,20
a2 为 0,1,20,50,4,5
则 a1表示以下区间[0,1] [3,6] [10,20]
a2表示以下区间[0,1] [20,50] [4,5]
则a1,a2的重叠部分为[0,1] [4,5],其长度为2
函数foo要求返回重叠区间的长度。上例中为2.
要求:
详细说明自己的解题思路,说明自己实现的一些关键点。
写出函数foo原代码,另外效率尽量高,并给出代码的复杂性分析。
限制:
al1和al2的长度不超过100万。而且同一个数组的区间可能出现重重叠。
如a1可能为 0,5, 4,8, 9,100, 70,80
使用的存储空间尽量小。
2 多人排成一个队列,我们认为从低到高是正确的序列,但是总有部分人不遵守秩序。如果说,前面的人比后面的人高(两人身高一样认为是合适的),那么我们就认为这两个人是一对“捣乱分子”,比如说,现在存在一个序列:
176, 178, 180, 170, 171
这些捣乱分子对为 <176, 170> , <176, 171> , <178, 170> , <178, 171> , <180, 170> , <180, 171> ,
那么,现在给出一个整型序列,请找出这些捣乱分子对的个数(仅给出捣乱分子对的数目即可,不用具体的对)
要求:
输入:
为一个文件(in),文件的每一行为一个序列。序列全为数字,数字间用”,”分隔。
输出:
为一个文件(out),每行为一个数字,表示捣乱分子的对数。
详细说明自己的解题思路,说明自己实现的一些关键点。并给出实现的代码 ,并分析时间复杂度。
限制:
输入每行的最大数字个数为100000个,数字最长为6位。程序无内存使用限制。
二、下面是两道选做题,请根据自己的情况选择其中的一道作答(WEB方向请答第4道,其他职位方向答第3道)。
3
考虑一个在线好友系统。系统为每个用户维护一个好友列表,列表限制最多可以有500个好友,好友必须是这个系统中的其它用户。好友关系是单向的,用户B是用户A的好友,但A不一定是B的好友。
用户以ID形式表示,现给出好友列表数据的文本形式如下:
1 3,5,7,67,78,3332
2 567,890
31 1,66
14 567
78 10000
…
每行数据有两列,第一列为用户ID,第二列为其好友ID,不同ID间用”,”分隔,ID升序排列。列之间用”t”分隔。
要求:
请设计合适的索引数据结构,来完成以下查询:
给定用户A和B,查询A和B之间是否有这样的关系:B是A的二维好友(好友的好友)。
如上例中,10000为1的二维好友,因为78为1的好友,10000为78的好友。
详细说明自己的解题思路,说明自己实现的一些关键点。并给出实现的伪代码实现建立索引过程和查询过程,并说明空间和时间复杂度。
限制:
用户数量不超过1000万,平均50个好友。
4
有关系模式:User(userId, userName), Article(articleId, userId, title, content),Vote(articleId, score),User为用户关系,Article为用户发表的文章关系,Vote为文章得票关系,title为文章标题、score为得票数。
(1)用SQL语言查询所有没发表过文章的用户名;
(2)用SQL语言查询得票数大于100的所有文章标题,按得票数倒序排列;
(3)用SQL语言查询出发表文章数大于5,文章平均得票数大于100的用户名,按平均得票数倒序排列;
(4)设计这些表的主键、外键和索引,并指出上面三个查询所使用的索引。
(5)当用户数超过1000万,文章数超过1亿时,如何考虑存储及性能的改进和优化?
问题点数:20 回复次数:63 显示所有回复显示星级回复显示楼主回复
oo
为了名副其实,努力学习oo技术ing
等 级:
发表于:2007-09-10 14:57:361楼 得分:0
mark
TAOBO2
等 级:
发表于:2007-09-10 16:47:422楼 得分:0
第一道 用线段树做
第二道 是逆序对吧
第三道 可以用图做吧 输入数据很像一个邻接表 或用邻接矩阵做
TAOBO2
等 级:
发表于:2007-09-10 16:51:003楼 得分:0
不过第三题1000万,内存可能吃不消 改用稀疏矩阵
fflush
stdin
等 级:
发表于:2007-09-10 21:30:464楼 得分:0
第一题能想到的是先排序,由于同一数组内区间可能重叠,在排序的时候可以合并这些区间(我认为这样并不会影响结果,不知道对题目理解是否有误),最后得到两组有序的,不重叠的区间。扫描一遍这两个数组就可以得到重叠区间的长度
第二题实际上就是求数组中逆序对的个数,这个问题可以在O(nlogn)时间内解决,方法类似于归并排序采用的方法,这里提供以前实现的一个版本
C/C++ code
/*
Let A[1...n] be an array of n distinct elements. If i < j and A > A[j],
then the pair (i, j) is called an inversion of A.
The algorithm that determines the number of inversions in any permutation
on n elements in O(nlogn) worst-case time is given as inversions routines.
*/
template <typename T>
int _inv_merge (T * array, int left, int middle, int right)
{
//two arrays, array[left...middle] and array[middle...right]
int lcnt = middle - left + 1;
int rcnt = right - middle;
//calculate the number of inversion pairs (i, j), that is,
//left <= i <= middle and middle < j <= right
int inv_cnt = 0;
for (int li = left, ri = middle + 1; li <= middle; li++)
{
while (ri <= right && array[li] > array[ri])
++ri;
if (ri > right)
{
inv_cnt = inv_cnt + (middle - li + 1) * rcnt;
break;
}
else
inv_cnt = inv_cnt + ri - middle - 1;
}
//merge two arrays
T * larray = new T[lcnt];
T * rarray = new T[rcnt];
std::copy (array + left, array + middle + 1, larray);
std::copy (array + middle + 1, array + right + 1, rarray);
int i = 0, j = 0, k = left;
while (i < lcnt && j < rcnt)
{
if (larray < rarray[j])
{
array[k] = larray;
++i;
}
else
{
array[k] = rarray[j];
++j;
}
++k;
}
while (i < lcnt)
array[k++] = larray[i++];
while (j < rcnt)
array[k++] = rarray[j++];
delete [] larray;
delete [] rarray;
return inv_cnt;
}
template <typename T>
int _inversions (T * array, int start, int end)
{
int inv_cnt = 0;
if (start < end)
{
int mid = (start + end) / 2;
inv_cnt = _inversions (array, start, mid) + _inversions (array, mid + 1, end);
inv_cnt += _inv_merge (array, start, mid, end);
}
return inv_cnt;
}
template <typename T>
inline
int inversions (T * array, int size)
{
return _inversions (array, 0, size - 1);
}
gzc9047
刮边植物人
等 级:
发表于:2007-09-11 07:14:465楼 得分:0
貌似百度的笔试题目都一个样,我的同学也是这4个题……
xuegao007
┥一个人要走多远,历经多少沧桑才会累;一个人要想多久,历经多少挫折才会懂┝
等 级:
发表于:2007-09-11 10:04:336楼 得分:0
mark
li1gang11
等 级:
发表于:2007-09-11 14:05:297楼 得分:0
重点是第3题。感觉不好做。不知道有什么思路?
li1gang11
等 级:
发表于:2007-09-11 14:07:448楼 得分:0
fflush说得不错,重点是第3题。
libany
紫心灯
等 级:
发表于:2007-09-11 14:14:009楼 得分:0
1 完成函数
size_t foo(unsigned int *a1, size_t al1, unsigned int* a2, size_t al2)
其中a1和a2都为无符号数组,al1和al2为数组的长度,数组的长度为偶数。
无符号数组由一对数字区间组成。如下例:
a1 为 0,1,3,6,10,20
a2 为 0,1,20,50,4,5
则 a1表示以下区间[0,1] [3,6] [10,20]
a2表示以下区间[0,1] [20,50] [4,5]
则a1,a2的重叠部分为[0,1] [4,5],其长度为2
函数foo要求返回重叠区间的长度。上例中为2.
没发现[4,5]重叠啊
hfutz
等 级:
发表于:2007-09-12 12:27:1210楼 得分:0
说[4,5]重叠是因为它已经包含在[3,6]里面了
laughable
Iv
等 级:
发表于:2007-09-15 12:07:0511楼 得分:0
MARK
edwin_edwin
edwin
等 级:
发表于:2007-09-16 10:59:0812楼 得分:0
假设a1: A1,A2,...,An (共n个)
a2: B1,B2,...,Bm (共mg个)
for (int i=0; i <m; i++)
{
if (Bi > = A1)
{
if (Bi+1 <= A2)
{
区间(Bi, Bi+1)
}
else if (Bi < A2) //隐含Bi+1 > A2的情况
{
区间(Bi, A2)
}
}
}
这里有个隐含条件,就是 A2一定大于A1 (A2> A1)!
先对a1数组的每一个区间在a2的每一个区间里找“交集” ,然后再对所有产生的“交集”求“并集”,最后计算所有“并集”的长度和。
li1gang11
等 级:
发表于:2007-09-17 12:03:4513楼 得分:0
第3题。不知道有什么思路?????????
li1gang11
等 级:
发表于:2007-09-18 10:19:2114楼 得分:0
第3题。不知道有什么思路?????????
li1gang11
等 级:
发表于:2007-09-18 15:31:5315楼 得分:0
第3题。不知道有什么思路?????????
krfstudio
等 级:
发表于:2007-09-18 16:03:5816楼 得分:0
关于第一题,
a1表示以下区间[0,1] [3,6] [10,20]
a2表示以下区间[0,1] [20,50] [4,5]
重叠的空间应该是 [0,1], [4,5], [20,20] 吧,题目有问题???
li1gang11
等 级:
发表于:2007-09-18 19:39:2917楼 得分:0
题目绝对没问题。
lasttimes
等 级:
发表于:2007-09-19 02:21:1518楼 得分:0
第3题的思路
现有的表是表示:A的所有好友的ID(好友为单向)
可以另建一个表示:加A为好友的所有ID
建新表应该遍历一次原表就可以了,
这样查找B是否为A的二维好友可以这样:
在原表中查找A的所有好友ID,在新表中查找所有加B为好友的ID,如果得到的两个ID列表中有重复的就说明B为A的二维好友
li1gang11
等 级:
发表于:2007-09-19 11:56:3419楼 得分:0
建新表就是比较麻烦的。
blessyou312
等 级:
发表于:2007-09-19 17:02:3120楼 得分:0
今天晚上百度来我们学校,不知会出什么题,去看看.
szlhj
等 级:
发表于:2007-09-19 21:27:5821楼 得分:0
现在大学的数据结构越来越差,第三题明显是邻接表数据结构,是表示图的一种数据结构。
查找A,B是否二维好友相当于从接点A出发--> 邻节点(好友)--> 邻节点(好友的好友)
就是图的两层深度遍历
loops
迷茫
等 级:
发表于:2007-09-19 23:43:3022楼 得分:0
第3题:
开个friends=new int[N*500]的大数组,
对于A的每个好友,去那个好友的好友列表里面二分查找就可以。
li1gang11
等 级:
发表于:2007-09-20 15:05:5223楼 得分:0
blessyou312 :
百度出什么题了,一定要告诉我啊???
Microsoft777
TMD倒分被抓了
等 级:
发表于:2007-09-20 20:06:0624楼 得分:0
mark
skill_215
等 级:
发表于:2007-09-21 23:13:5725楼 得分:0
别想了,刚去被BS回来,没一道题一样的
bigc2000
公元2005年4月9日
等 级:
发表于:2007-09-26 14:06:3926楼 得分:0
第三题:
用邻接表的话
1。设平均好友个数为m,那么一维维O(m),执行2遍就ok了,二维查询的平均复杂度显然为O(m*m)
2。用稀疏矩阵
这个早就不记得了,稀疏举证的加法,乘法都忘光了。
但这个题目应该使用稀疏举证。因为求二维甚至3维这个速度很快。
yshuise
等 级:
发表于:2007-09-28 12:34:3727楼 得分:0
第一题:
#include <ostream>
using std::cout;
using std::endl;
size_t foo(unsigned int *a1, size_t al1, unsigned int* a2, size_t al2)
{
for(int i = 0; i < al1; i++ )
{
int tx = a1;
int ty = a1[++i];
for(int j = 0; j < al2; j++)
{
int mx = a2[j];
int my = a2[++j];
if((tx > = mx && ty <= my) ¦ ¦ (tx <= mx && ty > = my))
{
cout < <tx < <" " < <ty < <"and" < <mx < <" " < <my < <endl;
}
}
}
}
yshuise
等 级:
发表于:2007-09-28 12:53:4928楼 得分:0
#include <vector>
#include <algorithm>
#include <iostream>
using std::vector;
using std::cout;
using std::endl;
using std::cin;
int cout_order_number(const vector <int> &a)
{
static n = 0;
for( vector <int> ::iterator itx = a.begin(); itx != a.end(); ++itx)
for( vector <int> ::iterator ity = a.begin() + itx ; ity != a.end(); ++ity)
if(*itx < *ity)
n++;
}
yshuise
等 级:
发表于:2007-09-28 12:54:5029楼 得分:0
帖子不允许编辑吗?郁闷。上面需要 return n;
yshuise
等 级:
发表于:2007-09-28 13:22:4230楼 得分:0
第3题:
可以利用图来做,不过用STL来做很方面。如:vector <vector <int> >
#include <vector>
#include <iostream>
using std::cout;
using std::cin;
using std::endl;
using std::vector;
void made_friendships(vector <vector <int> > &a)
{
cout < <"谁是谁的朋友 ,请输入:(用数字代替 0 除外,0 表示结束)" < <endl;
int cx;
int cy;
while( cin > > ci> > cy && cx != 0)
a[cx].push_back(cy);
}
void search_friendships(int cx, int cy)
{
vector <vector <int> > ::iterator it = a[cx].begin();
while(it != a[cx].end() )
if(**it == cy)
cout < <"find " < <cx < <" " < <cy < <endl;
cout < <"sorry!" < <endl;
}
}
yshuise
等 级:
发表于:2007-09-28 13:29:2631楼 得分:0
上面多写了一个} ,**it改为*it
daimarensheng
好好学习
等 级:
发表于:2007-09-29 14:04:2432楼 得分:0
不懂??????????????????????????????/
mmqmjy
莫名其妙
等 级:
发表于:2007-09-29 15:22:0833楼 得分:0
mark
caoxic
等 级:
发表于:2007-09-30 13:27:1034楼 得分:0
4楼的代码怎么帖的,我帖怎么就没有tab都没有了
oo
为了名副其实,努力学习oo技术ing
等 级:
发表于:2007-09-30 14:01:2435楼 得分:0
4楼的代码怎么帖的,我帖怎么就没有tab都没有了
=========================================
代码写好后,选中,点‘插入源代码’那个图标(选择颜色图标右边那个),选上你贴的代码的语言(c/c++等)
caoxic
等 级:
发表于:2007-09-30 14:42:2536楼 得分:0
明白了
red_berries
我再顶顶
等 级:
发表于:2007-10-01 15:57:2637楼 得分:0
第一题 如果区间范围小的话用hash来的比较快,如果区间范围大了就要考虑合并和排序区间了,实现是能实现,不过找个好的算法有点难.
第三题 如果不考虑空间大小的话觉得一个二维数组就行了,用邻接矩阵觉得没必要,多占好多的空间效率还低,不过这样效率还是比较低的,感觉最快的办法还是另开一个文件,和上面那个刚好相反,放的是加此ID好友的用户ID,这样查找起来就嗷嗷的快了,最后再来个hash表实现匹配查找,整个算法可以O(1)时间内找到,不过空间复杂度增加了一倍啊.另外这个问题的数据量也太大了,1000万 *50=5G啊,一个整形4字节就是20G,一个文件20G,读到内存要人命啊,这样就不能一次全读到内存了,还要看你读文件水平了
red_berries
我再顶顶
等 级:
发表于:2007-10-01 15:59:0738楼 得分:0
题目都不错哈
szlhj
等 级:
发表于:2007-10-01 16:09:4439楼 得分:0
ls有没有考虑到好友会频繁的增删,因此稀疏矩阵是行不通
shan1119
请输入你的社区昵称
等 级:
发表于:2007-10-01 16:45:5740楼 得分:0
测试
SQL codeselect * from tab;
myidc
酷睿数据
等 级:
发表于:2007-10-05 09:42:1941楼 得分:0
推荐2个分类信息网站。还可以加盟 只需要一个域名。可以加自己的ad
----------------------------------------
齐搜网-分类信息网-面面俱到的分类信息网
个人租房 ¦票务 ¦兼职 ¦跳蚤市场 ¦二手车 ¦生活黄页 ¦
----------------------------------------
http://www.allss.com.cn
----------------------------------------
http://www.city2city.com.cn
----------------------------------------
城市之间-分类信息网-面面俱到的分类信息网---
个人租房 ¦票务 ¦兼职 ¦跳蚤市场 ¦二手车 ¦生活黄页 ¦
love_cutezhou
等 级:
发表于:2007-10-05 10:44:4442楼 得分:0
mark一下~
liuchuan98
川流
等 级:
发表于:2007-10-06 10:35:3743楼 得分:0
第四题,这里将User用UserUU代替.
SQL code
1.
select userName
from userUU
where userId not in
(select userId
from Article);
2.
select Article.title
from Article,Vote
where Article.articleId = Vote.articleId
and Vote.score > 100
order by Vote.score DESC;
3.
select UserUU.userName
from UserUU,Article,Vote
where UserUU.userId = Article.userId
and Article.articleId = Vote.articleId
group by Article.userId
having count(Article.articleId) > 5
and avg(Vote.score) > 100
order by Vote.score DESC;
查询3还有些问题,帮忙改改
cnhexin
焰心
等 级:
发表于:2007-10-07 13:06:1344楼 得分:0
mark
myidc
酷睿数据
等 级:
发表于:2007-10-08 08:55:0645楼 得分:0
2个超强的分类信息网站!2站在手,万事不求
----------------------------------------
http://www.allss.com.cn
----------------------------------------
齐搜网-分类信息网-面面俱到的分类信息网
个人租房 ¦票务 ¦兼职 ¦跳蚤市场 ¦二手车 ¦生活黄页 ¦
----------------------------------------
http://www.city2city.com.cn
----------------------------------------
城市之间-分类信息网
成千上万的租房,车辆和跳蚤市场。火车票换票 兼职交友 等信息
======================================
wjlsmail
小脖领
等 级:
发表于:2007-10-09 17:25:5046楼 得分:0
Mark
Neo_1
等 级:
发表于:2007-10-09 18:20:3647楼 得分:0
3,
SQL code
select a.UserName from User a,(select c.UserID,Count(c.ArticleID) as ArticleCount,Sum(d.Score) as ScoreSum from Article c,Vote d where c.AlticleID = d.ArticleID group by c.UserID
) b where a.UserID = b.UserID and b.ArticleCount > 5 and b.ScoreSum/b.ArticleCount > 100
没有调试的~,不晓得正确不~
subsars
等 级:
发表于:2007-10-10 10:10:4448楼 得分:0
37楼red_berries说用hash法比较快,到底是怎么样的算法呢?
能不能具体说清楚一点啊?
subsars
等 级:
发表于:2007-10-10 10:31:1049楼 得分:0
第一题能想到的是先排序,由于同一数组内区间可能重叠,在排序的时候可以合并这些区间(我认为这样并不会影响结果,不知道对题目理解是否有误),最后得到两组有序的,不重叠的区间。扫描一遍这两个数组就可以得到重叠区间的长度
---------------------------------------------------------------------------------------------
这种方法的时间复杂度怎么来计算呢?
jackcao0628
光头和尚
等 级:
发表于:2007-10-10 15:39:2050楼 得分:0
Java code
public class Hello{
public static void main(String[] args){
System.out.println("Hello,World!");
}
}
red_berries
我再顶顶
等 级:
发表于:2007-10-10 22:40:2251楼 得分:0
我的意思是这样的,
对于第一题,定义4G个bit位,全置0,然后把在a1区间内的bit位置1,用 count统计重复区间的个数,先置0.
然后遍历集合2,
如果2区间对应的bit位的值为1,count++并将其bit位置0(防止重复),直到读完count2
为O(n),
对于第三题 后来又想了想,用二维数太占空间了,忽然想到操作系统课上那个用来管理文件磁盘空间的办法,可以这然定义一个结构,结构里是一个容量100的整形数组,然后是一个指针,这个指针用来动态申请一个容量400的整形数组,如果好友数目小于100时,这个指针为空,只有当好友数目大于100时再动态申请,这样就能合理的利用空间了,不过这样的数据结构在删除好友时有一点浪费时间,可能要移动许多数据,但觉得在实际中删除好友并不是常用的操作,还是可以接受的,至于用邻接矩阵,觉得操作有点复杂,当然哪种都可以.如果对速度要求比较高,我觉得还是另起一个文件,放加此ID好友的用户ID,这样还是比较快的
skypu
小土豆
等 级:
发表于:2007-10-11 14:39:4152楼 得分:0
小弟不才
这么写不就好啦
复杂度貌似是n!*n
恶,算法不是强项
顺便测试一下代码
int Fun()
{
int ncount = 0;
for ( int i = 0; i < N; i++ )
{
for ( int j = i; j < N; j++ )
{
if ( Mem > Mem[j] )
{
ncount++;
cout < < "{" < < Mem < < "," < < Mem[j] < < "}" < < endl;
}
}
}
return ncount;
}
skypu
小土豆
等 级:
发表于:2007-10-11 14:51:2353楼 得分:0
C/C++ code
int Fun()
{
int ncount = 0;
for ( int i = 0; i < N; i++ )
{
for ( int j = i; j < N; j++ )
{
if ( Mem > Mem[j] )
{
ncount++;
cout << "{" << Mem << "," << Mem[j] << "}" << endl;
}
}
}
return ncount;
}}
liuhking
虎虎虎
等 级:
发表于:2007-10-11 15:51:1354楼 得分:0
mark
mooninday
等 级:
发表于:2007-10-11 17:52:5055楼 得分:0
mark
hf1983
等 级:
发表于:2007-10-12 17:31:1356楼 得分:0
mark
zcws1987
等 级:
发表于:2007-10-13 17:10:1957楼 得分:0
C/C++ code
#include <iostream>
using namespace std;
void foo(unsigned int* a1,int al1,unsigned int* a2,int al2)
{
int count=0;
unsigned int *mem=(unsigned int*)malloc(sizeof(unsigned int)*100);
int p=0;
bool isInMem;
for(int i=0;i<al1;i+=2)
for(int j=0;j<al2;j+=2)
{
isInMem=false;
unsigned int temp[4] = {a1,a1[i+1],a2[j],a2[j+1]};
if(a2[j]>=a1[i+1] || a2[j+1]<=a1)
continue;
else
{
for(int k=1;k<4;k++)
{
unsigned int x=temp[k];
for(int t=k-1;t>=0&&x<temp[t];t--)
temp[t+1]=temp[t];
temp[t+1]=x;
}
for(int q=0;q<p;q+=2)
if(temp[1]==mem[q] && temp[2]==mem[q+1])
{
isInMem=true;
break;
}
if(!isInMem)
{
cout<<"["<<temp[1]<<","<<temp[2]<<"]"<<endl;
mem[p++]=temp[1];
mem[p++]=temp[2];
count+=(temp[2]-temp[1]);
}
}
}
cout<<count<<endl;
}
int main()
{
unsigned int a[]={0,5,4,8,9,100,70,80};
unsigned int b[]={2,7,20,50,4,5};
foo(a,8,b,6);
return 0;
}
我写的第一题的解法,大家看看,效率貌似不高[/code]
yclinuxmyf
等 级:
发表于:2007-10-16 09:44:1758楼 得分:0
mark
p0303230
初来乍到
等 级:
发表于:2007-12-14 10:33:3459楼 得分:0
mark
langya54
等 级:
发表于:2007-12-14 14:10:2360楼 得分:0
mark
heixia108
heixia
等 级:
发表于:2007-12-14 22:30:2361楼 得分:0
学习...
somer
等 级:
发表于:2007-12-17 16:46:3362楼 得分:0
red_berries ---第一题的算法很赞
i love it
zerglarva_aahha
无
等 级:
发表于:2007-12-17 18:03:5163楼 得分:0
4楼的不错,第一题和我想的差不多
第二题目是线性代数,第一章的,好象很容易,就是逆序数吧,用邻换和交换次数做大概就可以(记不清了)
3题:为什么大家都要用表做呢,我记得图有2种办法表示,这好象应该是用一种结构的数组做的(但记不得叫什么名字了)
此结构形状大致如下
stucte jg
{
sometype data;//这里存放本身的信息
jgcd **p;//这是个链表(数组也行,但麻烦,不过是可以2分查找),用来指向此点所指向的别的点,其总数就是此点的出度
jgrd **p;//这个与上类似,一般可以没这个链表,是入度(这个排列顺序也可以维护)
};
用上面的数组表示就变成2次顺序查找了,不然你用邻接矩阵表示,里面无效的数据那么多,查起来不累死(这是个人意见)
4题不熟悉,没兴趣做,可能也做不了,呵呵.